Speculatively load referenced files while "real" parsing is blocked on a <script src=> load
Categories
(Core :: DOM: HTML Parser, enhancement, P1)
Tracking
()
People
(Reporter: andershol, Assigned: mrbkap, NeedInfo)
References
()
Details
(4 keywords)
Attachments
(3 files, 8 obsolete files)
|
35.40 KB,
text/plain
|
Details | |
|
51.42 KB,
patch
|
mrbkap
:
superreview+
|
Details | Diff | Splinter Review |
|
3.67 KB,
patch
|
mrbkap
:
review+
mrbkap
:
superreview+
|
Details | Diff | Splinter Review |
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.0; en-US; rv:1.8.1) Gecko/20061010 Firefox/2.0
Build Identifier: Mozilla/5.0 (Windows; U; Windows NT 5.0; en-US; rv:1.8.1) Gecko/20061010 Firefox/2.0
It seems that when encountering a script-tag, that references an external file, the browser does not attempt to load any elements after the script-tag until the external script files is loaded. This makes sites, that references several or large javascript files, slow.
An example:
<script src='file1.js'/>
<script src='file2.js'/>
<img src='img1.gif'/>
<img src='img2.gif'/>
<script src='file3.js'/>
<img src='img3.gif'/>
Here file1.js will be loaded first, followed sequentially by file2.js. Then img1.gif, img2.gif and file3.js will be loaded concurrently. When file3.js has loaded completely, img3.gif will be loaded.
One might argue that since the js-files could contain for instance a line like "document.write('<!--');", there is no way of knowing if any of the content following a script-tag will ever be show, before the script has been executed.
But I would assume that it is far more probable that the content would be shown than not. And in these days it is quite common for pages to reference many external javascript files (ajax-libraries, statistics and advertising), which with the current behavior causes the page load to be serialized.
Therefore, wouldn't it be possible to parse the html speculatively as soon as it is availible and queue up any external files found?
Reproducible: Always
Steps to Reproduce:
1. Go to http://www.serveren.dk/load.php . The page references 4 external javascript files and a selectable number of images. All external files are very small but will be delayed 1 second.
Actual Results:
The page loads in a little over 4 seconds.
Expected Results:
The page should load in a little over 1 second as would have been possible if all elements were loaded in parallel.
Maybe external stylesheets are also loaded sequentially. I can't quite see why.
If the number of images is increased, notice that the images are loaded in a seemingly random order, and not in the order that they appear as would be expected. But that is probably another bug.
Comment 1•18 years ago
|
||
Sounds like a good idea, especially for users with high-latency connections. Many sites don't use the "defer" attribute (to be implemented in bug 28293). Furthermore, most scripts that use document.write (and thus can't use the "defer" attribute) write things other than "<!--", so the speculative loads will be correct. How hard would this be?
Comment 2•17 years ago
|
||
Steve Souders (YSlow) mentioned seeing this with Firebug, and that this would be a nice perf win on sites that load lots of external scripts. I wrote a small testcase before finding this bug, and verified that we're loading and executing each script sequentially. This sounds very vaguely like bug 84582. Except... I would guess that deferring a stylesheet load is safe for the parser, but since the script might be doing a document.write() the parser probably has to block until the script finishes executing (for the reason noted in comment #0). So the parser can't speculatively load the scripts, unless it has some way to roll-back parsing if one of the scripts did a document.write() or some such? If that's the case, this bug is probably a WONTFIX, and bug 28293 would be the proper solution to the problem.
Comment 3•17 years ago
|
||
I was imagining that a separate parser would do the speculative "look ahead for references to things we might want to load" parsing, to avoid the need for "rolling back".
Comment 4•17 years ago
|
||
Random thought: the "separate parser" could get away with just peeking at the next, say, 1024 bytes of data. The most common case is probably a block of sequential <script src=""> tags... Another thought was <link rel="prefetch" href="somescript.js">, but I think we currently only prefetch after page load.
Comment 5•17 years ago
|
||
As long as sites aren't depending on the details of the current behavior (e.g. using write('<!--') and images or some such for tracking), I think doing some sort of speculative prefetch is OK. The caveats:
1) We _must_ use the same algorithm to find URIs to prefetch that we use to
actually parse. To do otherwise invites XSS injection bugs.
2) We need to be pretty careful about what URIs we prefetch (e.g. no
javascript: URI prefetch).
Within those constraints, I think this is a great idea. It's particularly easy for CSS prefetch, because the CSS loader already coalesces loads...
Comment 6•17 years ago
|
||
JS may modify cookies, so if you do any speculative fetching, you'll need to verify that you used the correct cookies or something like that. And, it could be problematic if you do send the request with the wrong cookies :(
Comment 8•16 years ago
|
||
Rumor has it IE8 does something like this. http://www.stevesouders.com/blog/2008/03/10/ie8-speeds-things-up/
Comment 9•16 years ago
|
||
Looks like the relevant Safari bug is: http://bugs.webkit.org/show_bug.cgi?id=17480 Based on this blog post it looks like there's a nice gain: http://webkit.org/blog/166/optimizing-page-loading-in-web-browser/ I guess this is a good Mozilla2 feature.
Comment 11•16 years ago
|
||
One note is that we should do some testing to see how much parsing ahead we really want to do. There isn't that much benefit to starting more loads than we have connections to work with, I suspect, and the extra parsing time might matter.
Comment 12•16 years ago
|
||
(In reply to comment #11) > One note is that we should do some testing to see how much parsing ahead we > really want to do. There isn't that much benefit to starting more loads than > we have connections to work with, I suspect, and the extra parsing time might > matter. > Right I believe we want per-host priority queues and to prioritize script and css over images. The queues can make sure the number of sim. requests doesn't exceed the max number per host and also make sure as soon as a request completes we initiate the new one. Basically want to make sure we saturate the pipe and are never stalling. I think Bkap can do this in a long weekend while gallivanting through Europe. :-)
Comment 13•16 years ago
|
||
We effectively have the per-host thing already in the HTTP layer, and we can tweak the request priorities easily (script is already bumped up some). I was more saying that it might not be worth parsing the entire document twice. So once we get a little ahead of where the parser is right now blocked waiting on a script and get a few loads into the queue, it might be worth stopping the forward scan and waiting for either the queue to empty or the parser to catch up to us.
Comment 14•16 years ago
|
||
(In reply to comment #13) > We effectively have the per-host thing already in the HTTP layer, and we can > tweak the request priorities easily (script is already bumped up some). We should bump style sheets as well. > I was more saying that it might not be worth parsing the entire document twice. > So once we get a little ahead of where the parser is right now blocked waiting > on a script and get a few loads into the queue, it might be worth stopping the > forward scan and waiting for either the queue to empty or the parser to catch > up to us. Ya - we won't know until we try - but a simplified parser doing a look-ahead on a separate thread to basically stuff the network request queue so it is never stalled has got to be a win.
Comment 15•16 years ago
|
||
> We should bump style sheets as well.
Why? I'm not saying we shouldn't, but I'm interested in the reasoning. I guess stylesheet loads can block script execution (but not loading)...
Agreed on the separate thread, esp. given multi-core.
Comment 16•16 years ago
|
||
Figured that if CSS can cause reflow/re-layout than having the core layout done and images snap in will allow you to read the core content faster/have perceptual performance benefits. Generally saying images should be back of the line...
Updated•16 years ago
|
Updated•16 years ago
|
Comment 17•16 years ago
|
||
Blake, let us know if this is too big of a mouthful for 1.9.1 :)
Comment 19•16 years ago
|
||
What's the state of this? Currently there are a few browsers that are capable of doing both non-blocking script load and non-blocking script and stylesheet load, namely: Android, MobileSafari, and Safari nightlies. Chrome and Opera don't block on stylesheets and IE 8 doesn't block on scripts. I have access to some tests and test data if anyone wants it (it's not public yet). It would be great if we could be an early mover, especially with the performance advantages it provides.
Comment 20•16 years ago
|
||
(In reply to comment #18) > we really need this for mobile, blocking?'ing I did a quick try of running a Firefox3-based chrome on my Linux device (Monahans-LV, 128MB RAM, 3G network), and here's what I've got: Configurations & Page Loading Time: ---------------------------------------------------------------- orig pipe nojs best ---------------------------------------------------------------- pipelining.maxrequests 4 6 4 6 keep-alive.timeout 600 600 600 600 max-connections 4 6 4 6 max-connections-per-server 2 4 2 4 max-persistent-connections-per-server 2 4 2 4 max-persistent-connections-per-proxy 2 4 2 4 javascript.enabled true true false false ---------------------------------------------------------------- cnn.com 1'20" 33" 52" 23" news.com 46" 39" 40" 24" bbc.co.uk 59" 54" 20" 19" naver.com 1'12" 46" 37" 26" amazon.com 1'21" 57" 44" 27" ---------------------------------------------------------------- What I would like to show here is more on javascript's impact than the http pipelineing (see Bug 448805). With the same pipeline configuration, disabling javascript shows significant improvement on the page loading time. I've verified that disabling javascript will not download the javascript source files. By sharing this result, I am just trying to show that javascript impacts page loading time a lot, and resolving this <script src=> issue should be a significant contribution on page loading time on mobile devices (although there are other factors like parsing/interpretation time by SpiderMonkey etc...)
| Assignee | ||
Comment 21•16 years ago
|
||
This is a work in progress. It doesn't run yet. It *does* find URLs, but my latest round of changes before I attached it here broke it. Note the XXX comments.
| Assignee | ||
Comment 22•16 years ago
|
||
This is still a work in progress, but it loads cnn.com and actually seems to preload stuff. Still to do is address the rest of the TODO and XXX comments left in the patch and test a lot. Also, this patch makes us copy the script to the speculative parser instead of sharing the string. Doing this fixed a bunch of threadsafety problems, but we're now going to re-scan through parts of the document.
Should there be a separate bug to create a Tp test that imposes predictable artificial delay on resource loads?
Updated•16 years ago
|
| Assignee | ||
Comment 24•16 years ago
|
||
Comment 25•16 years ago
|
||
Comment on attachment 340486 [details] [diff] [review] patch v.5 void FireScriptAvailable(nsresult aResult) { - mElement->ScriptAvailable(aResult, mElement, mIsInline, mURI, mLineNo); + if (mElement) { + mElement->ScriptAvailable(aResult, mElement, mIsInline, mURI, mLineNo); No need for this null check, per our discussion. + fprintf(stderr, "We did preload a request for %s ...", str.get()); Take all these out before landing! :) - In nsScriptLoader::PreloadURI(): + StartLoad(request, aType); Check for failure here? +class nsSpecScriptThread : public nsIRunnable { Maybe spell out speculative in the name here, as it's not exactly obvious at first glance :) + enum PrefetchType { NONE, SCRIPT, STYLESHEET, IMAGE }; You said NONE is not needed here. + // The following members are shared across the main thread and the + // speculatively parsing thread. + Holder<PRLock> mLock; + Holder<PRCondVar> mCVar; + + CParserContext *mContext; mContext is not used on the parsing thread, only on the main thread. Fix the comment. + nsScannerIterator mBase; Not needed any more. - In nsSpecScriptThread::StartParsing(): + if (!mTokenizer) { + mThread = nsnull; + mLock = nsnull; + mCVar = nsnull; + return NS_ERROR_OUT_OF_MEMORY; Manually setting those members to null shouldn't be necessary here if the callers of this ensures that this object is deleted on failure to start parsing. + if (mNumConsumed > context->mNumConsumed) { context->mNumConsumed might not reflect reality, according to yourself. Comment to that effect and why we're still ok here in that case. Also, while talking through this it seemed like a good idea to protect ourselves against ever loading the same URI twice as a result of speculative parsing, as there are cases where we might parse the same data twice. - In nsSpecScriptThread::ProcessToken(CToken *aToken): + nsHTMLTag tag = static_cast<nsHTMLTag>(static_cast<eHTMLTokenTypes>(start->GetTypeID())); Seems like the eHTMLTokenTypes cast isn't needed there. - In nsParser::SpeculativelyParse(): + if (!mParserContext->mMimeType.EqualsLiteral("text/html")) { + return; Check to see we're not view-source or some other oddball parsing command here? + mSpecScriptThread->StartParsing(this); Check for errors and null out mSpecScriptThread, and spell out speculative in the name of this variable too! :) +nsScanner::nsScanner(const nsScanner& aScanner) + : mSlidingBuffer(new nsScannerString(*aScanner.mSlidingBuffer)), + mCurrentPosition(aScanner.mCurrentPosition), + mMarkPosition(aScanner.mMarkPosition), + mEndPosition(aScanner.mEndPosition), + mFilename(aScanner.mFilename), + mCountRemaining(aScanner.mCountRemaining), + mIncremental(aScanner.mIncremental), + mFirstNonWhitespacePosition(aScanner.mFirstNonWhitespacePosition), + mCharsetSource(aScanner.mCharsetSource), + mCharset(aScanner.mCharset), + mUnicodeDecoder(aScanner.mUnicodeDecoder), + mParser(aScanner.mParser) Not needed, since we now copy the string data and create a new scanner... r+sr=jst with that!
Comment 26•16 years ago
|
||
Or turn the printfs into PR_LOG stuff.
| Assignee | ||
Comment 27•16 years ago
|
||
Note that if you want to try the last version of the patch, you'll need to apply something like the following (which I haven't had a chance to test) due to the context->mNumConsumed problems jst mentioned:
diff --git a/parser/htmlparser/src/nsParser.cpp b/parser/htmlparser/src/nsParser.cpp
--- a/parser/htmlparser/src/nsParser.cpp
+++ b/parser/htmlparser/src/nsParser.cpp
@@ -419,19 +419,19 @@ nsSpecScriptThread::StartParsing(nsParse
nsScannerIterator end;
context->mScanner->EndReading(end);
nsScannerIterator start;
context->mScanner->CurrentPosition(start);
if (mNumConsumed > context->mNumConsumed) {
// We consumed more the last time we tried speculatively parsing than we
- // did the last time we actually parsed. Start again from where we left
- // off. We know that this is a valid position (not past the end).
- start.advance(mNumConsumed - context->mNumConsumed);
+ // did the last time we actually parsed.
+ PRInt32 distance = Distance(start, end);
+ start.advance(PR_MIN(mNumConsumed - context->mNumConsumed, distance));
}
if (start == end) {
// We're at the end of this context's buffer, nothing else to do.
return NS_OK;
}
CopyUnicodeTo(start, end, toScan);| Assignee | ||
Comment 28•16 years ago
|
||
This is an interdiff for jst's review comments. I'm going to update my tree and post a full diff in a little bit.
| Assignee | ||
Comment 29•16 years ago
|
||
This is the full patch with jst's comments addressed. I'll run it through mochitests and (assuming it passes) I'll check it in tomorrow.
| Assignee | ||
Comment 30•16 years ago
|
||
Comment on attachment 340863 [details] [diff] [review] jst's comments >- // Special hack for IBM's custom DOCTYPE. >+ // Speculativeial hack for IBM's custom DOCTYPE. Uh, clearly, this was a mistake from the renaming I did. :-) I've fixed it locally.
| Assignee | ||
Comment 31•16 years ago
|
||
Comment on attachment 340866 [details] [diff] [review] patch v1 Some overzealous deletion on my part combined with bug 444322 caused bad races and crashes. I'll post a new patch tomorrow (the one that I will be landing, hopefully).
| Assignee | ||
Comment 32•16 years ago
|
||
In the meantime http://hg.mozilla.org/users/mrbkap_mozilla.com/speculative-parsing tracks the problems mochitest finds.
| Assignee | ||
Comment 33•16 years ago
|
||
This passes mochitests. I'll check it in once the tree goes green again.
Updated•16 years ago
|
| Assignee | ||
Comment 34•16 years ago
|
||
http://hg.mozilla.org/mozilla-central/rev/961d90be2ba8
| Assignee | ||
Comment 35•16 years ago
|
||
I filed bug 457809, bug 457810, and bug 457811 as followups to this bug.
Comment 36•16 years ago
|
||
This has been backed out due to random crashing in talos and mochitest runs
Comment 37•16 years ago
|
||
A run on my non-debug build on my machine produced this crash report
Updated•16 years ago
|
Comment 38•16 years ago
|
||
Even though this only addresses blocking on <script/> and not <img/> or stylesheets, it has a significantly good impact on the testcases I use as mobile benchmarks - good stuff! I tried out the patch from comment 34, and measured it on a modeled edge wireless network (54/160kbit - 700 ms +/- 100ms rtt). The main datapoint is a cnn.com homepage snapshot from earlier in the summer. That html is 110KB.. it first loads 3 stylesheets, than a lot of external js (the first of which are prototype.js and scriptaculous.js) mixed with some more css, and finally starts mixing in dozens of more images (the first of which is cnn_com_logo.gif) with some more scripts (both included and external). There are 15 external js files in total. here are the highlights of the start times of significant GET events, with the GET of the HTML being T=0 (T in seconds) Control (9/30) Patched Improvement HTML 0 0 0 common.css 2.494 2.288 .206 main.css 2.494 2.288 .206 pgaleader.css 2.557 2.477 .080 prototype.js 15.392 5.226 10.166 scriptaculous.js 20.952 5.226 15.726 [..] cnn_com_logo.gif 53.293 37.377 15.916 [..] pageload-complete 78.527 63.345 15.182 Can't argue with a 19% improvement! Some open questions: 1] can we see idle network (and free connection) time in between receipt of the first image tag and its corresponding GET. That will help show that doing this for images too will also give a return. 2] Is there a negative impact on pages that dont have external scripts?
Do <img> tags block the parser? I wouldn't have thought so...
| Assignee | ||
Comment 40•16 years ago
|
||
(In reply to comment #38) > 1] can we see idle network (and free connection) time in between receipt of the > first image tag and its corresponding GET. That will help show that doing this > for images too will also give a return. I'm not sure about this. > 2] Is there a negative impact on pages that dont have external scripts? No, we won't even create a speculative parser if the parser is never blocked. (In reply to comment #39) > Do <img> tags block the parser? I wouldn't have thought so... <img> tags don't block the parser, but the faster we can start the loads, the less bad latency will affect the user.
| Assignee | ||
Comment 41•16 years ago
|
||
I still haven't reproduced the crash, but the stack Mossop posted shows us running events in an awkward place that could cause problems. This patch makes us: *) Use a threadpool, which deals with thread creation and deletion (and also puts a limit on the number of threads we'll create, which we want anyway). *) Not share the token allocator between threads. I don't know if this is necessary, but it's the last mutable data structure that we share and therefore is the last potential cause of bad heap corruption if things do go wrong.
Updated•16 years ago
|
Comment 42•16 years ago
|
||
blake - can you help me understand the image delay issue - I feel like I'm reading contrary things. Is the img submitted to the fetch queue immediately on parse, or does it wait for the js execution to finish?
Comment 43•16 years ago
|
||
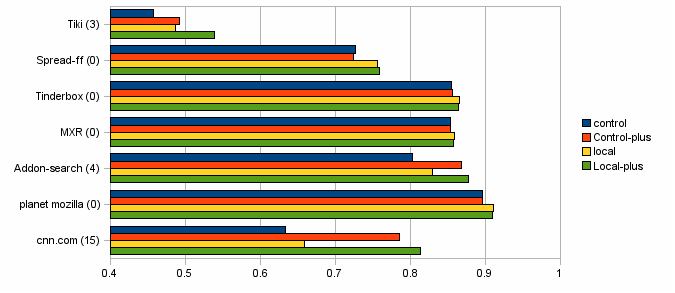
(In reply to comment #40) > > > 2] Is there a negative impact on pages that dont have external scripts? > > No, we won't even create a speculative parser if the parser is never blocked. yep - and the measurements bear it out. this rocks. check out: http://www.ducksong.com/misc/speculative-loader-efficiency-09302008.gif I used the same network to measure my usual 7 testcases. I used mobile builds and measured them each with "control" (mozilla-central), "control plus" (your patch added in), "local" (my local repo which is mozilla-central plus some pipeline patches from bug 447866 that are awaiting review), and "local-plus" (local with your patch added in.. interesting because your patch ought to exercise the pipelining code more) The X-axis is the "efficiency ratio" which is just a measure of how fast the download is compared to the theoretical max speed. Ideal is 1.0 but is not realistic - but the closer to 1.0 the better - .9 is a good goal. the name of each test has (N) after it, where (N) is the number of external js entries that are part of the page... N=0 saw no change, large N saw a large change as hoped. this is all very cool.
{kind=link}
| Assignee | ||
Comment 44•16 years ago
|
||
(In reply to comment #42) > blake - can you help me understand the image delay issue - I feel like I'm > reading contrary things. Is the img submitted to the fetch queue immediately on > parse, or does it wait for the js execution to finish? The image load starts when we create the content node for the image. That happens at some point during the parsing of the page. The parser doesn't wait for that to happen, though. We'll continue creating content nodes as that happens. I'm not sure if that clears things up, though.
| Assignee | ||
Comment 45•16 years ago
|
||
Doing a mochitest run on the last patch revealed a leak due to the order of destruction in the speculative parsing thread. This patch fixes it by reordering the members, which destroys the tokenizer before the token allocator. It also adds an explicit call to the thread pool's Shutdown member in case some crazy circular reference meant a sub-thread held it alive.
Comment 46•16 years ago
|
||
The image and stylesheet issue is merely about whether we'll prefetch them while being blocked. Right now, while the parser is blocked we only prefetch scripts (which is likely the biggest win, since if we get them by the time we restart the parser, we won't have to block again).
| Assignee | ||
Comment 47•16 years ago
|
||
I think that stylesheets are pretty important too, since they act as script blockers.
| Assignee | ||
Comment 48•16 years ago
|
||
I ran into a last-minute issue where if an nsPreloadURIs event had been dispatched and not processed by the time the parser was terminated (e.g. for shutdown) we'd try to preload a URI for a torn-down document.
| Assignee | ||
Comment 49•16 years ago
|
||
All right, here's the status.... I pushed speculative parsing again as <http://hg.mozilla.org/mozilla-central/rev/0f8280132011>. Now, we appear to be consistently passing mochitest (and we'd better, considering the number of times that I ran mochitests over the past day). However, there seems to be a random crash during Tp. I can't figure out how to run the Tp tests locally or otherwise and I have no other information. As I type this, there have been green cycles on Linux and Mac but it appears that there is another 4 hour wait before the Windows talos builds finish. Further, one of the Mac talos builds is orange with a crashed Tp. It's 3am now and since (judging by the current statistics) we should have perf numbers across the board, I'm going to tentatively mark this fixed and try to investigate the Tp bustage tomorrow.
| Assignee | ||
Comment 50•16 years ago
|
||
(we now have 1 green and 1 orange Windows talos box)
| Assignee | ||
Comment 51•16 years ago
|
||
Many thanks to Sayrer for providing the stacks that helped find this. I've committed it as <http://hg.mozilla.org/mozilla-central/rev/4ed163dabf93>.
Comment 52•16 years ago
|
||
Not sure if you have a bug tracking the followup work, but your "comment out spec parsing" change seems to have turned all the Talos boxes green.
Can we switch a Talos machine to building with symbols, and get a crash reporter log, if not a core file? That would likely help a bunch in figuring out what's going on. Adding Alice for such assistance, not sure if anyone else has access to make that change.
Comment 54•16 years ago
|
||
Talos machines don't build at all, they're just testing the builds from the build machines. Those machines build with symbols, but they don't upload them.
Comment 55•16 years ago
|
||
But we should be able to throw a nightly build at a talos box.
Comment 56•16 years ago
|
||
If you can do that, great. But you'd still have to manually submit the crash report since we don't have bug 379290 fixed.
Updated•16 years ago
|
Comment 57•15 years ago
|
||
verified FIXED on builds: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.2a1pre) Gecko/20090413 Minefield/3.6a1pre ID:20090413031052 and Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.2a1pre) Gecko/20090413 Minefield/3.6a1pre ID:20090413031052
Comment 58•15 years ago
|
||
ack, here's the build ID for Shiretoko Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b4pre) Gecko/20090413 Shiretoko/3.5b4pre ID:20090413031313
Comment 59•4 years ago
|
||
This change ended up having negative privacy implications when combined with its effect on JS-generated meta CSPs. In order to support this use case, I'll be filing a spec with PrivacyCG to make it so that sites can opt-out of speculative loading with a no-speculate attribute. I'll update this issue with a link to the GitHub discussion later
Updated•4 years ago
|
Comment 60•4 years ago
|
||
JS-generated meta CSPs.
Which don't work at all if script is disabled, right?
Disabling this specific sort of speculation is a huge performance hit on a typical web page, especially on anything resembling a mobile (i.e. high-latency) connection. I suggest doing some testing of the resulting behavior before suggesting that it be added, even as an opt-in.
Comment 61•4 years ago
•
|
||
And I should note that mrbkap has not been working on Gecko for years, now, so it's not clear to me what effect, if any, the needinfo on him will do. Especially since it did not come with a clear description of what information was needed. What are you trying to achieve with comments in this bug, exactly?
Comment 62•4 years ago
|
||
I just meant to ping everyone on this issue, since it's from so many years ago. I don't really need info.
Disabling this specific sort of speculation is a huge performance hit on a typical web page
Correct, which is why this would be optional and should only be enabled for 'modern' (e.g. explicitly marked up with defer/async where applicable) web pages instead of 'typical' web pages.
I suggest doing some testing of the resulting behavior before suggesting that it be added, even as an opt-in.
I'll be sure to post an update in this thread w/perf benchmarks & compat tests once I get to that point 👍
Comment 63•4 years ago
|
||
Please don't post anything in closed bugs except "here's a link to the not-closed bug tracking whatever we still need to track".
And please file a new bug describing the behavior changes you want. This is not the right place to discuss them.
That said, your assumptions about whether users care about performance of "non-modern" websites are wrong, and penalizing all such websites because some sites want to write meta CSP from JS (which is generally a bad idea to start with) is likely a non-starter. You might be able to convince people to add a "go real slow" switch; making it the default is a much tougher sell.
| Assignee | ||
Comment 64•4 years ago
|
||
(Trying to clear the needinfo)
Description
•