Expose file dependency information in searchfox
Categories
(Webtools :: Searchfox, enhancement)
Tracking
(Not tracked)
People
(Reporter: kats, Unassigned)
Details
Attachments
(3 files)
I've been interesting in tracking down which header files are the most common culprits for world-rebuilds. i.e. header files that are widely included throughout the tree, and are frequently modified.
I finally managed to get some results and I think it might be worthwhile to expose some of this information in searchfox. At least we can say "this header is included by <x> downstream .cpp files". Technically we can could even provide an include/dependency graph showing the chain of includes and such.
Anyway I have WIP patches that I may clean up and try landing if there's interest.
https://github.com/staktrace/gecko-dev/commits/includes has three patches to the clang-plugin. These create an __INCLUDEINFO__ folder inside the generated mozsearch_index folder that have include information. For each file that clang processes, it records the files included into that one. So e.g. __INCLUDEINFO__/mfbt/Maybe.h has things like mfbt/Alignment.h and /usr/include/c++/9/new.
And then https://github.com/staktrace/mozsearch/commits/includeinfo has a tool added to mozsearch that slurps in these files and can produce dependency information (e.g. for a given file, how many downstream consumers are there).
If we want to expose this information the biggest remaining problem (as always) is UX.
| Reporter | ||
Comment 1•4 years ago
|
||
/cc Simon as maybe relevant to his interests.
Comment 2•4 years ago
•
|
||
This sounds super useful!
I believe :sg has been using https://github.com/aras-p/ClangBuildAnalyzer for analysis as the source of information for his bugs improving header inclusions, etc.
I've definitely thinking it would be useful to be able to have explicit analysis metadata about files/compilation units. I'd mainly been thinking that the crossref process would aggregate/derive this metadata for files as part of the process of cross-referencing[1], with us introducing some new symbol scheme that corresponds to files. This could make sense for this scenario given that to implement bug 1418001 we'd likely want an analysis record that lines up directly with the include tokens rather than as part of a separate metadata store. This should also ideally work with merge-analyses in a reasonably straightforward way.
That said, we totally do now have an infrastructure for per-file info that is totally distinct from the analysis data as part of the test info and coverage info enhancements. If we want the info to live separately or it's just most pragmatic to land what you already have, it's just a question of modifying https://github.com/mozsearch/mozsearch/blob/master/tools/src/bin/derive-per-file-info.rs and https://github.com/mozsearch/mozsearch/blob/master/tools/src/bin/output-file.rs to propagate and emit the data, respectively, if it makes sense to integrate with that pipeline. output-file could also just pull the data directly from the __INCLUDEINFO__ structure, but the upside to the centralized per-file JSON (and single aggregating per-file super JSON) is it's already JSON formatted stuff that we could start serving up from router.py/its successor without any special logic.
1: In the fancy branch I do have it propagating/deriving information and it seems like it would be reasonably straightforward to similarly make sure that the includer and includee can know about each other.
Comment 3•4 years ago
•
|
||
For UX, I'd propose starting with an Accordion style UI in the super navigation panel. Accordions typically have a mutually exclusive thing going on so only one panel is open at a time (which would be sticky via localStorage). While this can be infuriating, it's likely a practical solution for something like this where:
- There's a good chance the amount of data included in the thing that expands is large enough that attempting to view the contents of 2 accordions at the same time is impractical in terms of a) wildly inconsistent content heights for different files, and b) the heights being large enough so that you can't see both pieces of data at the same time.
- In most focused use-cases of trying to deal with includes, you're probably not trying to fix everything about the file all at once and an explicit switch between accordion panels isn't the end of the world.
- We can include concise summary information in the title that's visible when the accordion is collapsed.
- Accordions should result in visceral reactions in UX professionals, who will then feel a moral imperative to help fix the problem.
PS: Note that accordions don't have to be mutually exclusive, example.
Comment 4•4 years ago
|
||
(In reply to Kartikaya Gupta (email:kats@mozilla.com) from comment #1)
/cc Simon as maybe relevant to his interests.
Thanks a lot! Indeed this sounds very interesting!
As asuth pointed out, I have been using ClangBuildAnalyzer to find "expensive" headers, which have a large aggregated parse time. However, this does not take the history of changes (or any other hg data) into account.
In particular, when thinking about whether a header might be split up into a stable (rarely changed) and an unstable (often changed) part, this might be very helpful to direct the effort.
Independently from the modification information, having an overview of how often each header is included would be very interesting as well. ClangBuildAnalyzer doesn't provided this information (though it could probably be easily extended to do this as well).
| Reporter | ||
Comment 5•4 years ago
|
||
(In reply to Andrew Sutherland [:asuth] (he/him) from comment #2)
I'd mainly been thinking that the crossref process would aggregate/derive this metadata for files as part of the process of cross-referencing[1], with us introducing some new symbol scheme that corresponds to files.
Ah, this makes a lot of sense. I hadn't really thought about this approach but it seems good. I can update my patches to generate that instead.
(In reply to Andrew Sutherland [:asuth] (he/him) from comment #3)
- Accordions should result in visceral reactions in UX professionals, who will then feel a moral imperative to help fix the problem.
Hah, I wish! :) I'm not a big fan of accordions in general but it's probably a reasonable thing here given the use-cases won't usually involve switching between navigation and info often.
Comment 6•4 years ago
•
|
||
(In reply to Kartikaya Gupta (email:kats@mozilla.com) from comment #5)
Hah, I wish! :) I'm not a big fan of accordions in general but it's probably a reasonable thing here given the use-cases won't usually involve switching between navigation and info often.
I think this is a general UX need we're going to have going forward, so it certain wouldn't hurt to try and do better. Specifically, the problem is "I have this extra information that could be useful, but where can I put it so it doesn't hide information the user actively needs/wants, doesn't infuriate them, but they can also discover the information is available?"
Options I've tried so far:
- My initial approach pre-dating the fancy branch was the "mega menu" approach where each menu option in the traditional searchfox popup menu provides contextual information in an pane that's attached to the menu and appears to be part of the menu.
- A pop-up menu with horizontal tabs (on the fancy branch) but where the mouse placement advantage was not yet implemented/optimized. github does something similar now but more optimized for the mouse. The general feedback on this was that it occluded way too much of the source code people were looking at, so it would be better at the top/bottom or sides.
- As shown in the attachment Showing info in multiple optional panes that at the top. The panes are optionally present if they have data. My goal here was to make it so that as you scrub over the searchfox default menu we'll restrict the visible pane to the one you're hovering over. Extra panes that don't correspond to a searchfox menu item with a textual link would get an icon in a gutter at the top of the menu above the current options (and so all muscle memory is maintained). I also figured there could be a way to persistently disable/collapse panes the user isn't interested in. (The gray vertical bars are intended to allow for such toggling.)
{kind=link}
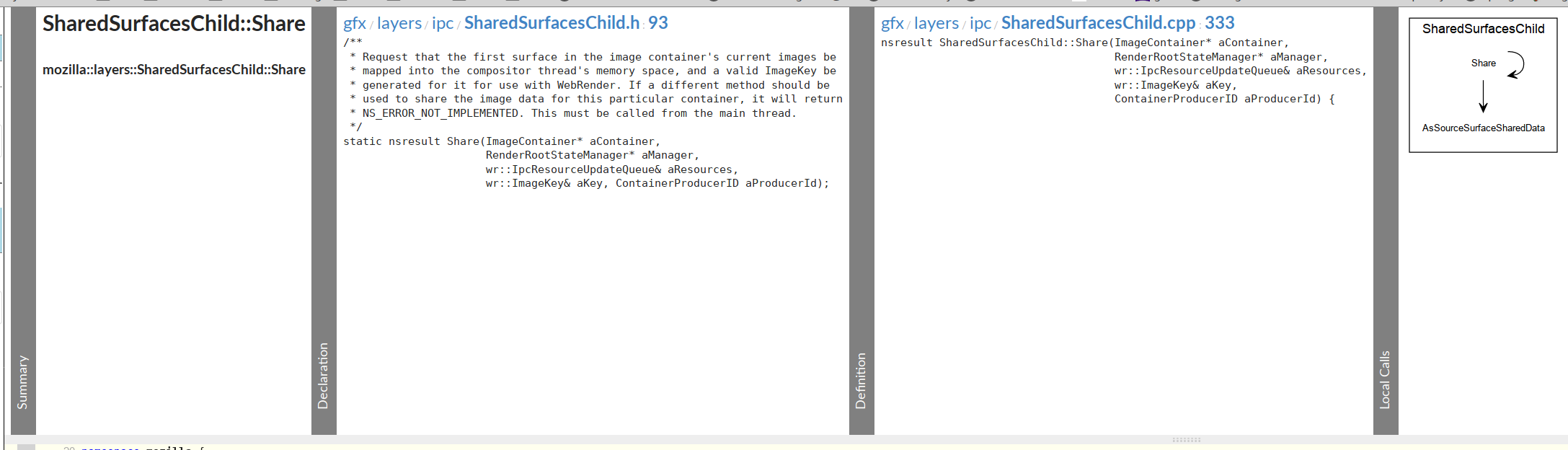{kind=link}
Example for that:
[ class diagram icon ] [ local calls diagram ] [IPC interaction diagram]
[ "Go to definition of Foo" / shows definition peek text on hover ]
[ "Go to declaration of Foo" / shows declaration peek text on hover ]
One of the things that's been clear about the current fancy branch approach is that the header at the top is not working either. I've been trying in vain to try and make it work because I currently use 2 4k monitors with 2 side-by-side Firefox windows on each monitor, each using Tree Style Tab in the sidebar and with a layout.css.devPixelsPerPx of 1.25. This nets me a document.body.offsetWidth of about 1291 and a document.body.offsetHeight of 1599 which doesn't leave much room on the sides, only on the top. I think I'll have to bite the bullet and resize the active Firefox searchfox window to be more like 2/3rds of the screen at an offsetWidth of 1830 or full screen of 2827. Then the panes can live in the super-duper navigation panel.
If we went down the road of scrubbing over the searchfox menu as a means of selecting info pane visibility, one can imagine then adding a "show other inclusions of this header" menu option when clicking on #includes which would correspond to showing all the dirty details about the header and its many inclusions. I imagine the first menu option would still want to be "Go to this header". In terms of showing the information about the header's inclusions when it's the file we're already displaying, perhaps we could make a menu show up when you click on the filename's breadcrumb, or perhaps to the right of the filename we put a little bubble labeled "(meta)" or we put one bubble per useful info panes we have for the file. I know I've discussed with Simon how we might put things like "(coding guidelines)" up there for our DOM Workers & Storage components which have their own more specific guidelines.
Comment 7•4 years ago
|
||
As a quick addendum, I'm realizing that tying the extra info to the menu may be a useful strategy for accessibility purposes as well.
Comment 8•4 years ago
|
||
Technically we can could even provide an include/dependency graph showing the chain of includes and such.
This would also be very helpful in understanding where it may be possible to break a dependency chain!
| Reporter | ||
Comment 9•4 years ago
|
||
| Reporter | ||
Comment 10•4 years ago
|
||
I used graphviz to render the Document.h dependency graph to see how usable it is when the graph has thousands of nodes. Answer: not super usable. But if you zoom way out and pan around you can sort of see some headers standing out as having lots of outgoing edges, so eliminating those from the dependency graph likely helps. But there might be multiple paths to that header, and finding all those paths is probably best done with a separate graph. Needs some sort of min-cut algorithm probably.
Comment 11•4 years ago
|
||
I think hierarchical edge bundling is frequently used in cases like this. See https://www.data-to-viz.com/graph/edge_bundling.html and https://www.researchgate.net/figure/Dependency-graph-with-hierarchical-edge-bundling-depicting-packages-as-vertices-and_fig3_313423777 with https://vega.github.io/vega/examples/edge-bundling/ being a live example of using the Vega library which is state-of-the-art for custom non-graphviz visualizations.
Comment 12•4 years ago
|
||
Edge bundling might be one option, or some interactive approach, which allows to collapse/expand certain branches. Or a semi-interactive approach, which can be used to reduce the graph beforehand by imposing some weight threshold on the edges.
Another alternative might be using a local viewer like https://gephi.org/? Something integrated directly in searchfox would definitely be preferable, but I am not sure if the necessary effort is feasible.
Comment 13•4 years ago
|
||
(In reply to Simon Giesecke [:sg] [he/him] from comment #12)
Something integrated directly in searchfox would definitely be preferable, but I am not sure if the necessary effort is feasible.
In a pre-fancy-branch world, I think the most pragmatic solution would likely be that the indexing process generates static HTML/SVG/image files and these can be linked to from any of the following places, possibly including a tiny preview image of what the graph looks like (via img tag/similar):
- Navigation side-pane with the concise data about what's going on.
- Up by the bread-crumbs on a file page.
- In the pop-up menu for header files includes.
- In the directory listings.
These static files could potentially be standalone HTML documents using Vega to do super fancy things or other stuff. (Possibly via search params, like https://searchfox.org/mozilla-central/extras/includes/cool-vega-stuff.html?file=all-the-include-data.json.)
In my planned Utopian post-fancy-branch world, we could integrate all of this and :smaug will throw us a parade ;)
Description
•